Going Serverless: AWS and Compelling Science Fiction
11-10-2016
This is a companion blog post to a talk I gave to the Boulder Python Meetup group about the infrastructure that runs Compelling Science Fiction. Slides from that talk can be found here. Hopefully you can use some of these tools to create something new as well!
Compelling Science Fiction is run entirely on extremely inexpensive Amazon Web Services (AWS). There are currently three primary use cases that I have:
- Serving web pages that contain the site. This is easily achieved by using the Amazon S3 feature that allows you to serve static web pages from an S3 bucket.
- Accepting and managing submissions from authors.
- Reading through the queue ("slush") of stories that authors submit.
It's the last two items on that list that I'll be talking about today, because they both use the same basic infrastructure. That infrastructure is diagrammed below:
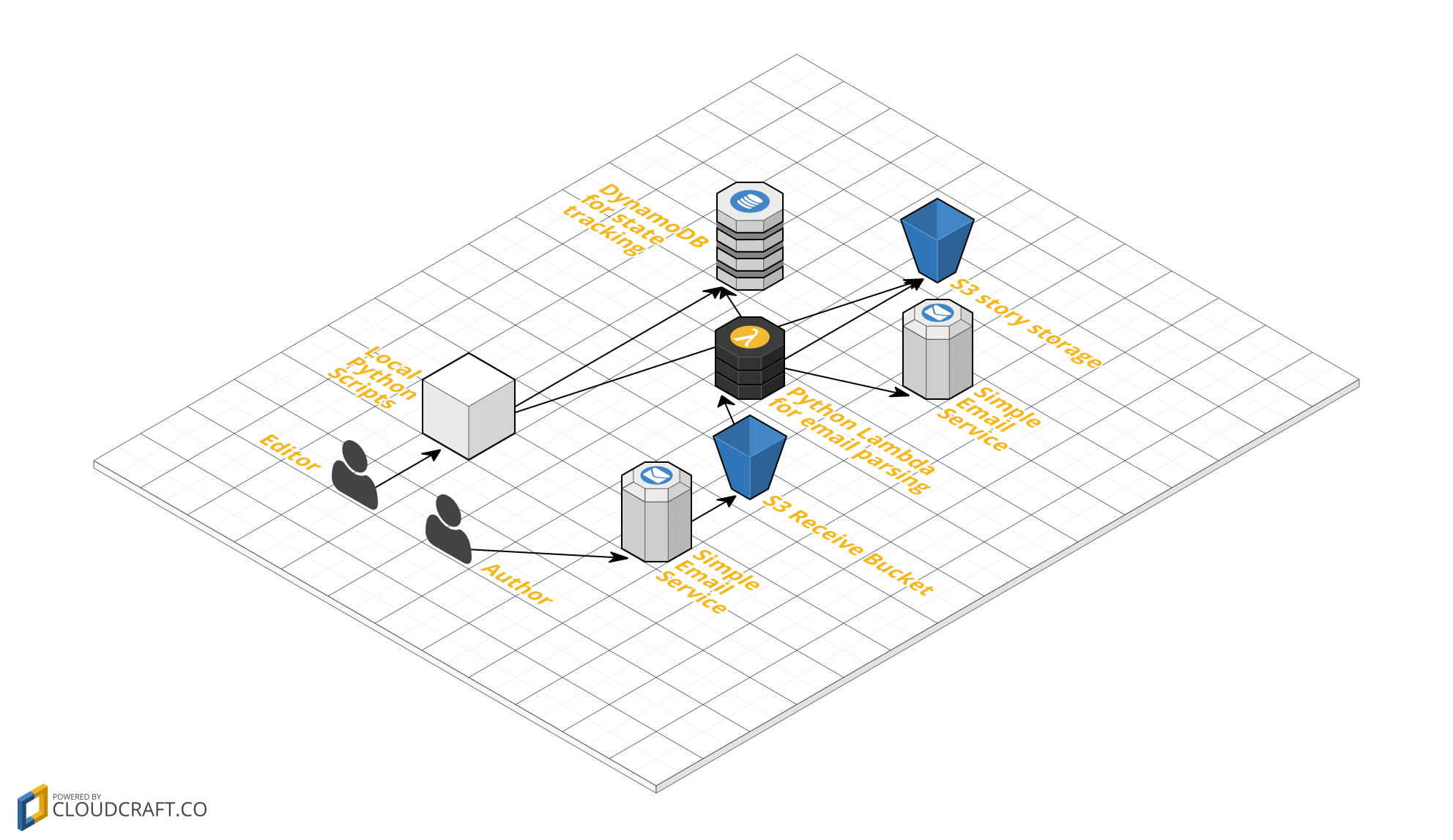 As you can see, I use four different Amazon Web Services: the Simple Email Service (SES), Simple Storage Service (S3), Lambda, and DynamoDB. I'll touch on all of the ways we use these services, but AWS Lambda is the most important, because it allows us to glue together all the services with Python without provisioning any servers.
As you can see, I use four different Amazon Web Services: the Simple Email Service (SES), Simple Storage Service (S3), Lambda, and DynamoDB. I'll touch on all of the ways we use these services, but AWS Lambda is the most important, because it allows us to glue together all the services with Python without provisioning any servers.
Process Flow
The process flow for a story is as follows: an author sends an email to "submissions@compellingsciencefiction.com" (please read our guidelines before submitting your story), and the email is routed to an S3 bucket by SES. The S3 bucket then triggers the submission processing lambda, which I'll give a bare-bones version of below. The lambda parses the raw MIME email, separating it out into constituent parts, which it then sends to an S3 bucket for storage. The Lambda also creates a DynamoDB entry (DynamoDB is a non-relational database that AWS provides). The DB entry contains story metadata, including author email, state (initially "unread"), time received, S3 location, and a reference ID. Finally, the Lambda emails the author a confirmation notice, and also emails a notification to me (the editor).
At this point the story is in S3 and has metadata stored in Dynamo. To evaluate the story queue, I get on my local computer and run some simple python scripts that access the queue by looking at timestamps in the database and pulling the oldest story from S3. I evaluate the story, and then use another python script to update the database with the new state of the manuscript. The process then starts all over again.
Lambda: the System Core
AWS Lambda:
- lets you run code without provisioning or managing servers
- only charges you for the compute time you consume (100 ms increments)
- runs code in discrete chunks, which is a versatile way to create many types of applications and backend services
- takes care of everything required to run and scale your code with high availability
- allows you to set up your code to automatically trigger from other AWS services or call it directly from any web or mobile app
All of the features above make Lambda a great option for services that are idle most of the time, but can have huge spikes in users. For more high-level info about Lambda, you can read this FAQ.
At it's core, an AWS lambda function is just an encapsulated chunk of code that you upload to Amazon. Therefore, the code must have well-defined inputs and outputs. On the input side, each lambda must define a handler. This is the entry point into your code. The handler must take two parameters: an “event” and a “context”. The “event” parameter is used to pass in event data to the handler. This parameter is usually a dict. It can also be a list, str, int, float, or NoneType. The “context” parameter is used to provide runtime information to your handler (timing callbacks, CloudWatch data, invocation info, etc.). This parameter is of the LambdaContext type. The context is not always used (and in fact I don't use it at all in my system). There are two types of lambda invocation: “Event” and “RequestResponse”. The former is asynchronous, while the latter is synchronous. The asynchronous type is the most used -- other entities generally don't wait around for Lambdas to respond.
Below is the code used in the Compelling Science Fiction submission system. It's not fully-functional, because I've stripped out the pieces that are not necessary for the understanding of how the AWS services fit together. This is the code that provides the functionality described in the 'Process Flow' section above. I've also added comments to the code below for ease of understanding.
import relevant_modules
def lambda_handler(event, context):
# Get the bucket name from the event
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.unquote_plus(event['Records'][0]['s3']['object']['key']).decode('utf8')
response = s3.get_object(Bucket=bucket, Key=key)
# Get a message object structure tree from an open file object
msg = email.message_from_file(response["Body"])
# parse the MIME message and send to s3:
for part in msg.walk():
# Do a bunch of parsing of each email part, storing the relevant ones to s3
# Get the dynamoDB table for submissions info
table = boto3.resource("dynamodb").Table("compelling_submissions")
# send record of this email to dynamoDB:
dynamo_item = {'id':ukey,'email':emailaddr,
'evaluation_state':0,
'timestamp':decimal.Decimal(time()),
's3_postfixes': s3_postfixes}
table.put_item(Item=dynamo_item)
# finally, send a reply email to manuscript sender and a notification for the editor:
emailclient = boto3.client("ses")
emailclient.send_email(PARAMS_FOR_AUTHOR)
emailclient.send_email(PARAMS_FOR_EDITOR)
I hope this was interesting, and please let me know if you use any of these concepts in an application of your own! I'm always interested in hearing about new creations.
Joe Stech
Editor
If you enjoyed this post, please consider subscribing to Compelling Science Fiction. Your support helps us pay authors who bring great content into the world.